
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- 미지아
- 트랙포인트
- k8s
- 시놀로지
- lubuntu
- synology
- 외장SSD
- 포토박스
- Thunderbolt3
- 가상컴퓨터
- 울트라나브
- centos
- 쿠버네티스
- TRACKPOINT
- Rocky LInux
- Code-Server
- SSD인클로저
- 탁상시계
- lenovo
- 미니스튜디오
- IoT
- VMM
- k0s
- 빨콩
- Kubernetes
- 스마트 디스플레이
- ACASIS
- talos linux
- USB4.0
- 원격
- Today
- Total
테크믈리에의 리뷰 공간
[K8S / Rancher 강좌] 4-1. RKE1 (Docker) 환경에서 Nvidia GPU 사용 방법 본문
[K8S / Rancher 강좌] 4-1. RKE1 (Docker) 환경에서 Nvidia GPU 사용 방법
테크믈리에 2023. 8. 20. 16:16
서론
이번 글에서는 RKE1을 통하여 K8S 환경을 구축하는 방법을 먼저 다룬 다음에 Nvidia GPU를 해당 클러스터에서 인식시키는 방법까지를 진행하도록 하겠다. RKE1은 Docker 기반 환경으로 Nvidia GPU를 인식시키기 위해서는 Nvidia-Docker 환경을 구축해야하고 K8S 환경에서는 Nvidia Device Plugin 혹은 Nvidia GPU Operator를 올려야할 필요성이 있다. RKE1 구축 이후의 과정은 Kubeadm 등 다른 Docker 기반 K8S 환경에서도 동일하게 적용되는 만큼 참고해두면 도움이 될 것이다.
이번 4-1에서는 Nvidia Device Plugin을 통하여 Nvidia GPU 환경을 구축하는 것을 연습해보고 4-2에서는 Nvidia GPU Operator를 통하여 Nvidia GPU 환경을 구축하는 것을 연습해볼 예정이다. 두 가지 방식에는 Time Slicing 지원부터 시작하여 몇가지 차이점이 있기 때문에 본인에게 필요한 방식에 따라 RKE1으로 구축하였더라도 GPU Operator를 올리는게 나을수도, RKE2로 구축하였어도 Device Plugin으로 올리는게 나을수도 있다. 자세한 차이는 아래 링크 등을 참고해보도록 하자.
From the kubernetes community on Reddit: What is the difference between nvidia device plugin and GPU operator?
Explore this post and more from the kubernetes community
www.reddit.com
RKE1 클러스터 구축
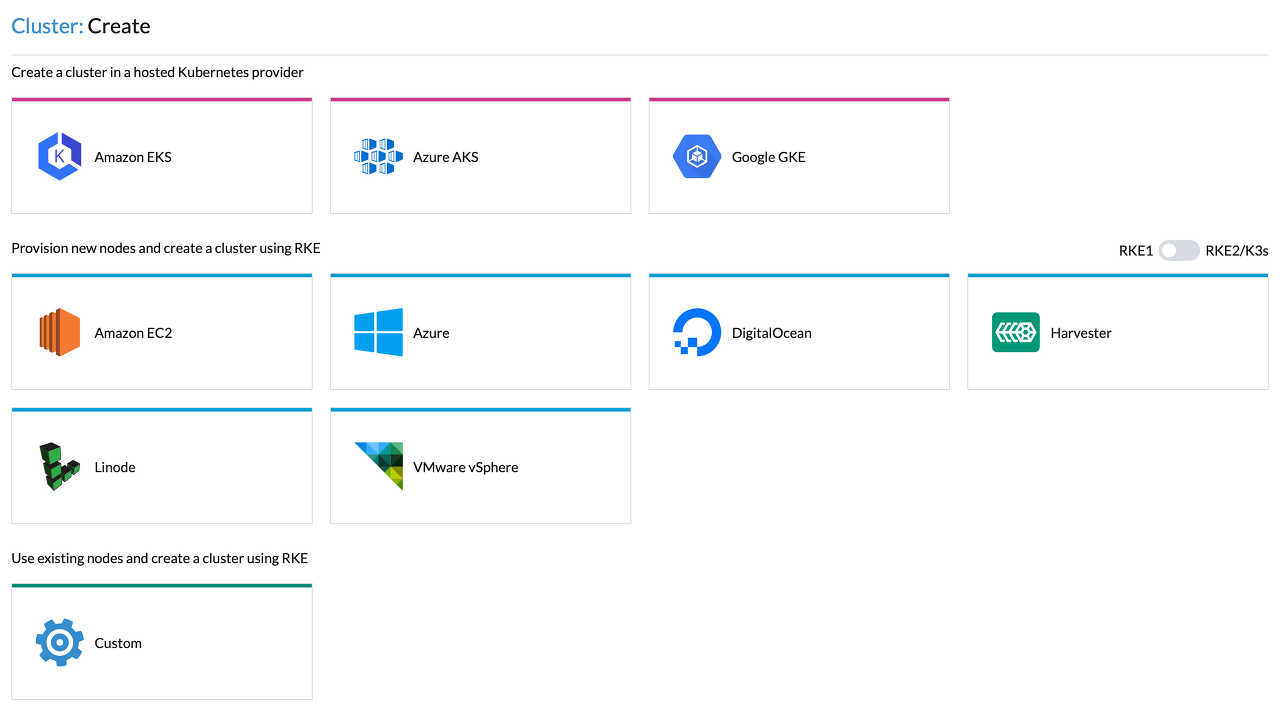
앞서 준비해둔 Rancher의 웹 화면에서 Create를 누르면 위 화면이 나올 것이다. 여기서, Provision new nodes and create a cluster using RKE의 우측 끝을 보면 RKE1 / RKE2/K3s가 보이는데 RKE1을 선택해주고 Custom을 선택하도록 하자.
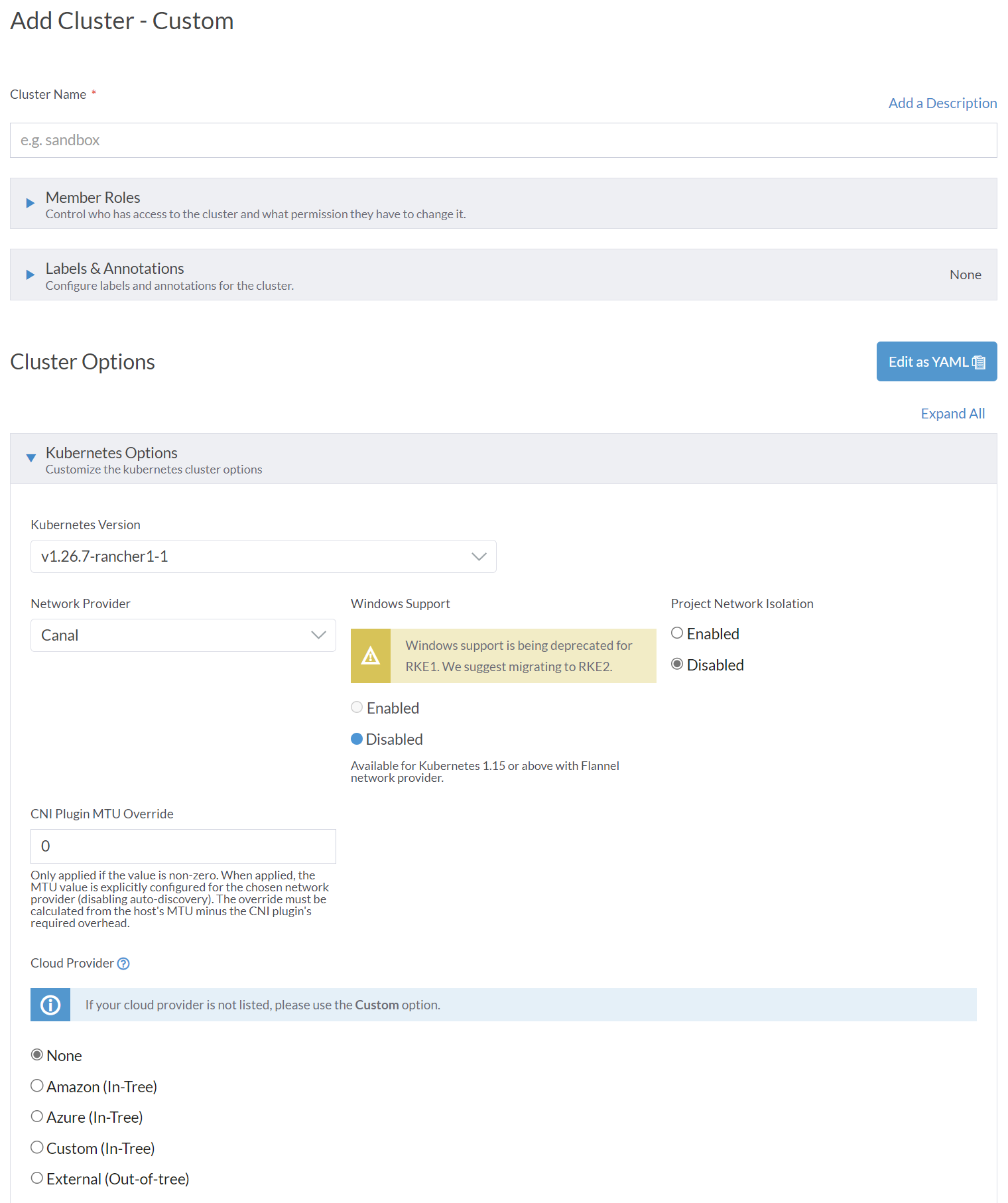
그러면 위와 같은 화면이 나올텐데, Cluster Name을 작성한 다음 Kubernetes Version에서 원하는 버전을 지정하도록 하자. 참고로 이 시리즈의 마지막에서 다룰 KubeFlow의 경우에는 v1.25까지만 지원하기 때문에 최신 버전을 올리게 되면 호환되지 않을 것이다.
Network Provider의 경우 개인적인 경험으로는 Rancher RKE1에서는 Canal이 Calico보다 안정적이었던 것 같다. 그 외 나머지 옵션은 필요에 따라 변경하면 되고, 간단하게 구축하고자 한다면 크게 건들이지 않아도 된다.
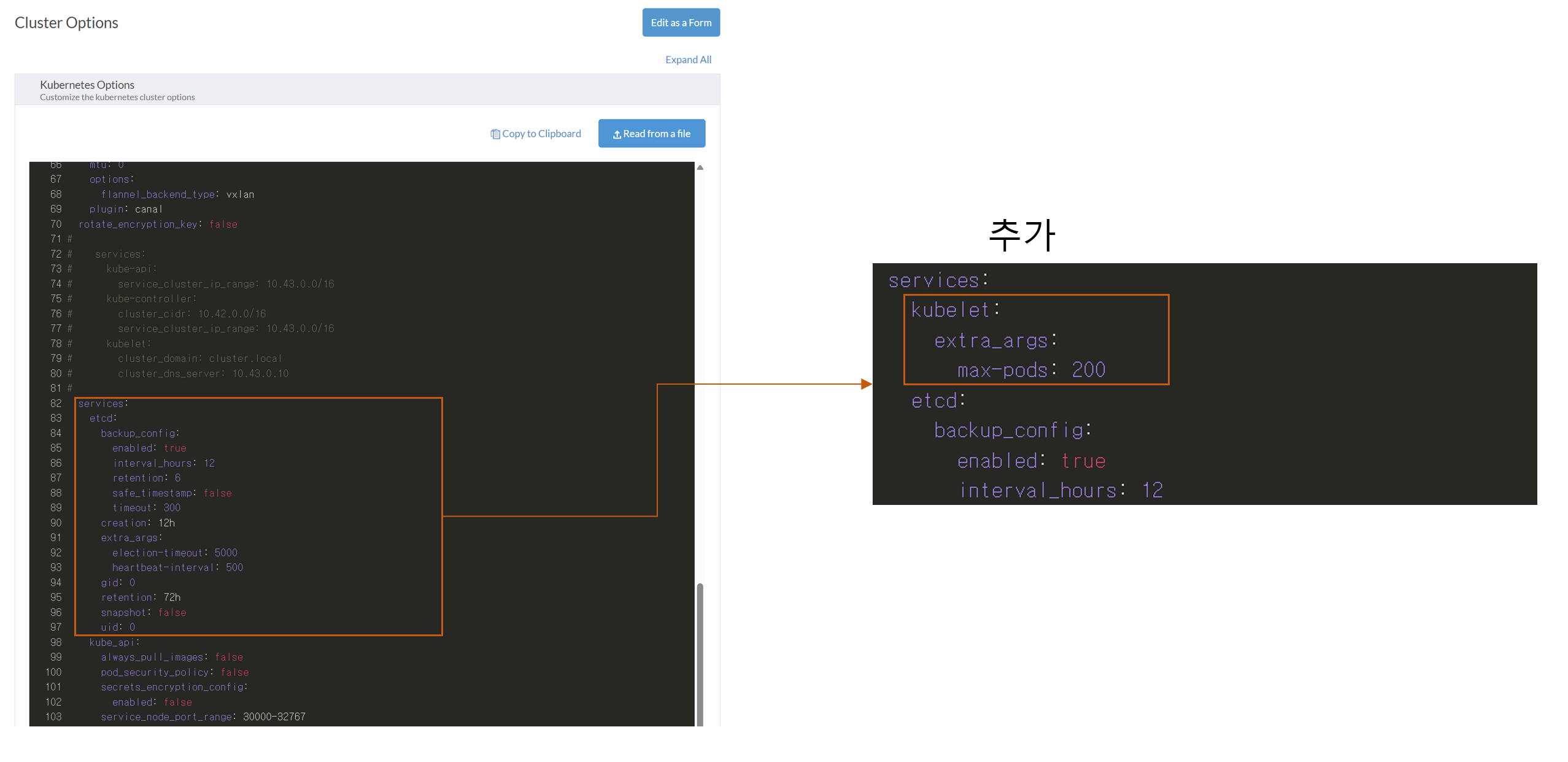
그 외에 필수적인 것은 아니지만, 해주면 좋은 작업으로는 등록가능한 최대 Pod의 갯수를 늘리는 것이 있다. 기본적으로 Rancher에 설정된 최대 Pod 갯수는 사실 기본적으로 올라가는 클러스터 관리용 Pod부터 시작해서 몇 개 올리다보면 금방 차기 때문에 최소 200개 이상으로는 올려주는 것이 맘이 편할 것이다. 변경을 하기 위해서는 Cluster Options에서 Edit as YAML을 눌러 위 화면과 같은 편집창을 띄운 다음 services 항목 아래에 우측과 같은 내용을 삽입하면 된다.
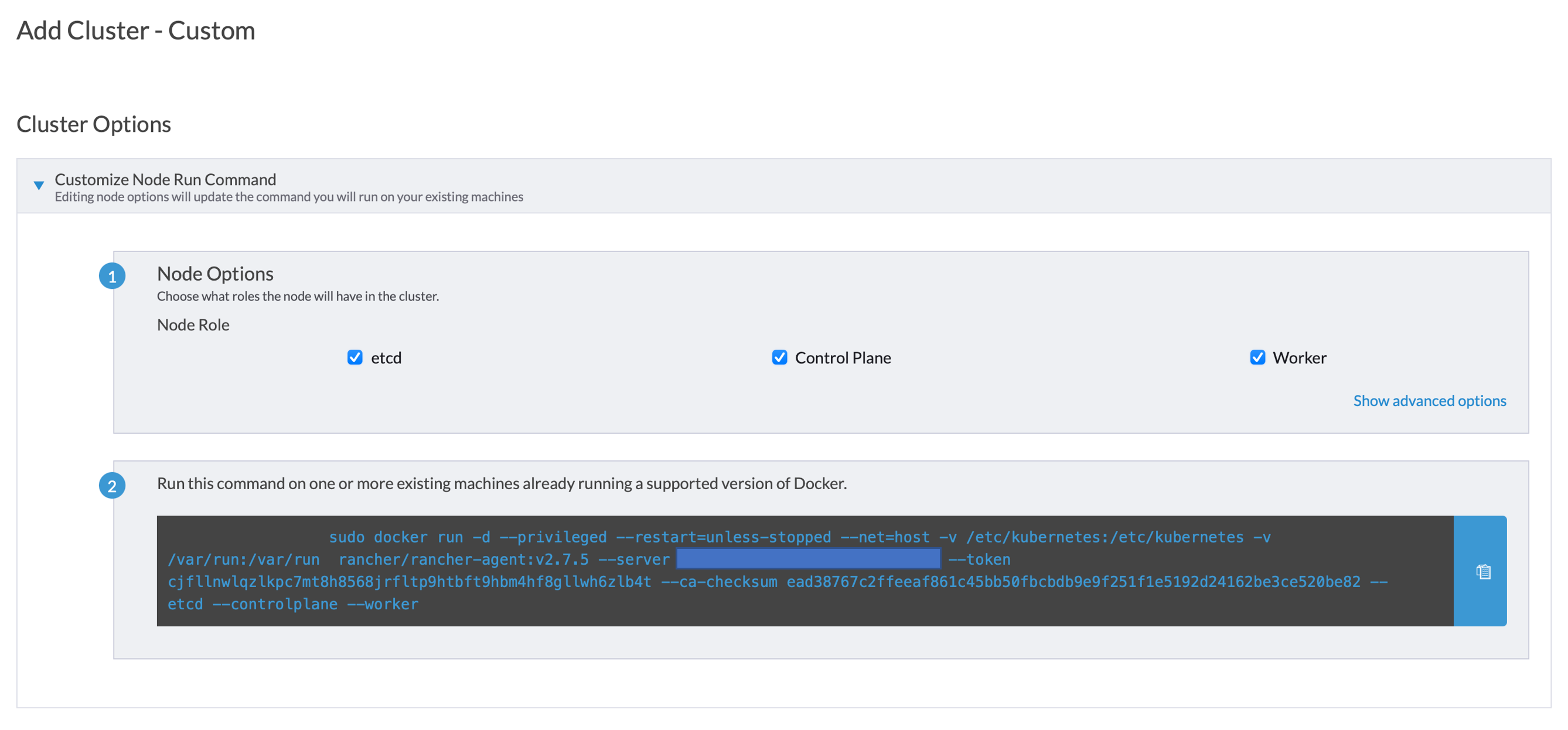
클러스터 구축을 완료한 다음에는 위와 같은 화면이 뜨는데, 참가시키고자 하는 Worker Node의 Role을 정한 다음 하단의 명령어를 복사해가서 실행한다면 클러스터에 노드가 추가된다. 참고로, 노드의 이름은 기본적으로 각 노드에 정해진 Hostname으로 나오게 될텐데 관리자가 각 노드를 구별하기 쉽게 하기 위해서는 Show advanced options에서 각 노드별로 이름을 지은 다음 참가시키는 것이 권장된다.
Nvidia Docker 설치
이제는 Worker Node의 Nvidia GPU를 Docker에서 인식할 수 있게 해줘야한다. 이를 위해 필요한 것이 Nvidia에서 제공하는 Container Toolkit이다.
distribution=$(. /etc/os-release;echo $ID$VERSION_ID) \
&& curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \
&& curl -s -L https://nvidia.github.io/libnvidia-container/$distribution/libnvidia-container.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list우선은 위 명령어를 통하여 Nvidia Container Toolkit의 GPG 키를 등록하도록 한다.
sudo apt-get update
sudo apt-get install -y nvidia-container-toolkit
sudo nvidia-ctk runtime configure --runtime=docker
sudo systemctl restart docker그 다음에는 위 명령어를 사용하여 Nvidia Container Toolkit을 설치하고 Docker에서 Nvidia runtime을 기본 Runtime으로 지정해준 다음 도커를 재실행하도록 하자.
sudo docker run --rm --runtime=nvidia --gpus all nvidia/cuda:11.6.2-base-ubuntu20.04 nvidia-smi정상적으로 실행되었다면 위 명령어 결과가 터미널에 바로 nvidia-smi를 입력한 것과 동일하게 나타날 것이다.
Node Feature Discovery
이제 Docker에서의 Nvidia GPU 사용이 준비되었으니, 남은 것은 K8S에서도 Nvidia GPU를 쓸 수 있게끔 해주는 것이다. 이에 앞서 설치해줘야하는 것은 Node Feature Discovery라는 툴이다. 이 툴은 클러스터 내 각 노드의 사양을 분석하여 Node Label로 추가해주는 역할을 한다.
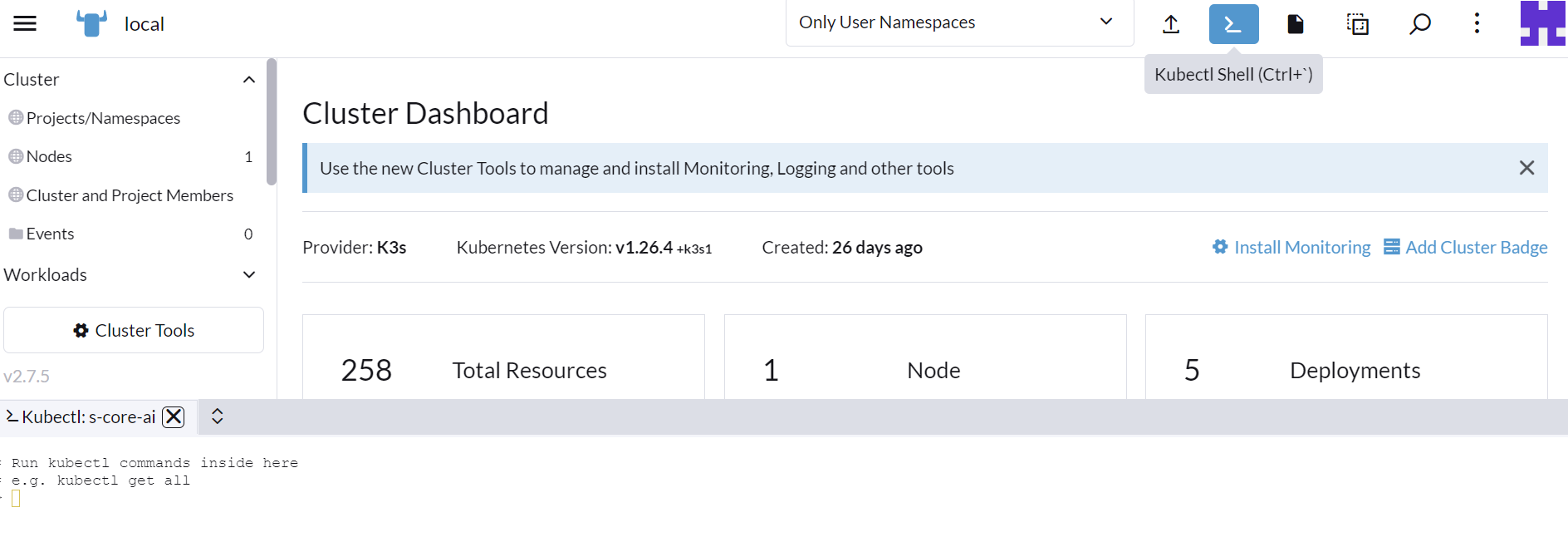
Rancher 페이지에서 원하는 클러스터 대시보드에 들어간 다음 최상단을 보면 Kubectl Shell이라는 버튼이 있을 것이다. 이를 누르면 하단에 터미널이 나타나게 되는데, 여기서 kubectl, helm 등의 명령어를 쓸 수 있다. 여기에 다음 명령어를 입력하도록 하자.
helm repo add nfd https://kubernetes-sigs.github.io/node-feature-discovery/charts
helm repo update
helm install nfd/node-feature-discovery --namespace node-feature-discovery --create-namespace --generate-name조금 기다리면 Helm을 통해 NFD의 설치가 완료될 것이며, 그 상태에서 기지개좀 피고 잠깐 놀다 오면 아래와 같이 각 노드의 Labels 항목에서 CPU부터 OS의 정보 등 다양한 정보를 확인할 수 있다.
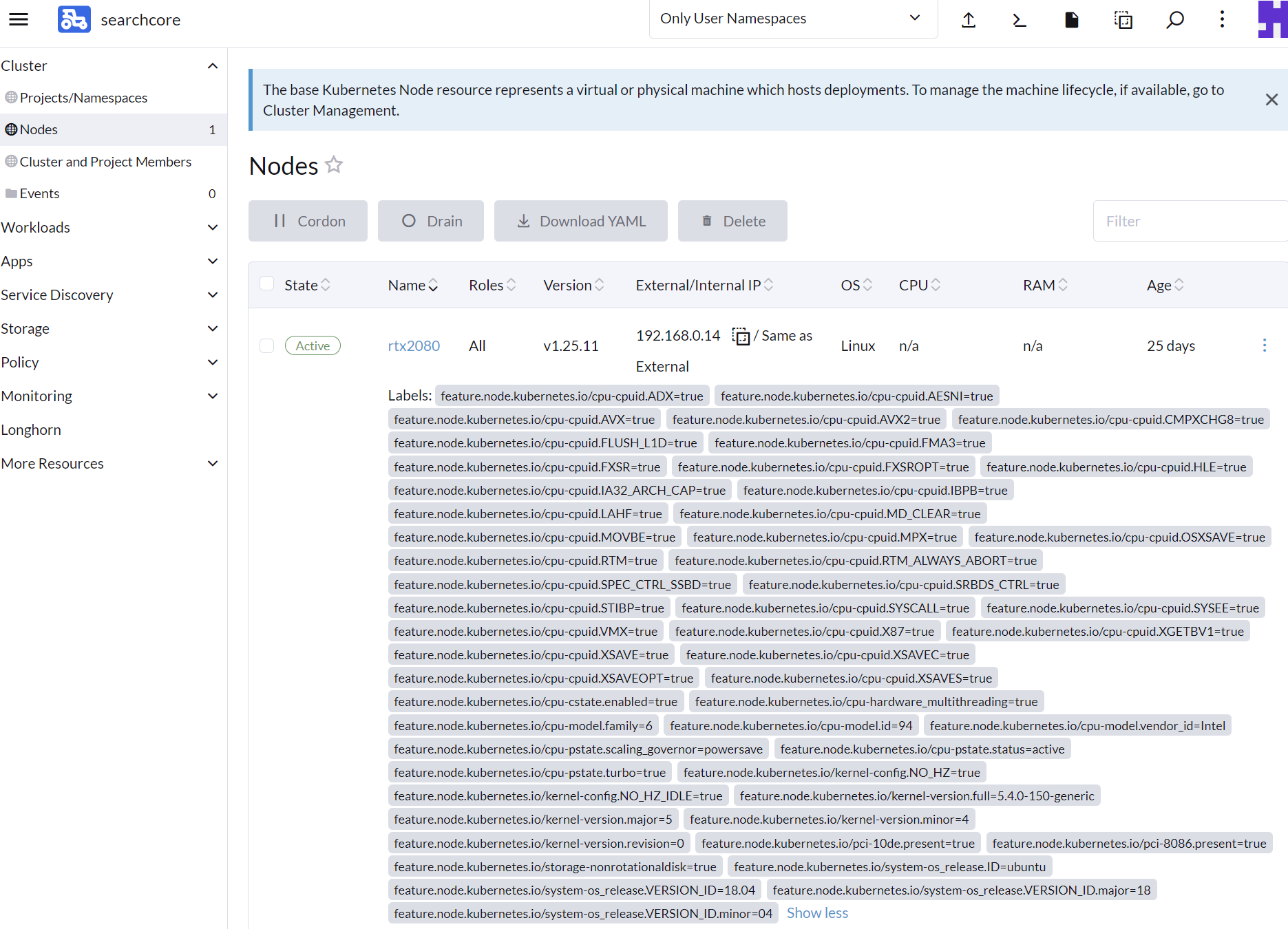
Nvidia Device Plugin 설치
Device Plugin을 올릴 때는 NFD에 이어서 GPU Feature Discovery도 올려줘야할 필요성이 있다.
helm repo add nvgfd https://nvidia.github.io/gpu-feature-discovery
helm repo update
helm upgrade -i nvgfd nvgfd/gpu-feature-discovery \
--version 0.8.1 \
--namespace gpu-feature-discovery \
--create-namespaceGPU Feature Discovery를 올린 다음에는 Nvidia Device Plugin을 올리도록 하자.
helm repo add nvdp https://nvidia.github.io/k8s-device-plugin
helm repo update
helm install nvdp nvdp/nvidia-device-plugin \
--version=0.14.0 \
--namespace nvidia-device-plugin \
--create-namespaceNFD와 마찬가지로 각 Pod들이 작업을 하는데에는 시간이 필요하기 때문에 농땡이 치다 돌아오도록 하자. 성공적으로 올라갔다면 Node Labels에 이젠 GPU 이름도 노출이 될 것이다.
만약 예제를 통해 Nvidia GPU 사용 가능 여부를 확인해보기 위해서는 아래와 같은 Pod를 한번 올려보도록 하자.
# gpu_test.yaml
# kubectl apply -f gpu_test.yaml
apiVersion: v1
kind: Pod
metadata:
name: ubuntu-18.04
spec:
containers:
- name: ubuntu
image: nvidia/cuda:11.1.1-devel-ubuntu20.04
command:
- "/bin/sleep"
- "604800"
resources:
limits:
cpu: "2"
memory: "8G"
nvidia.com/gpu: "1"kubectl exec -it ubuntu-18.04 -- /bin/bash
nvidia-smi마침글
이번 글에서는 RKE1으로 클러스터를 구축하는 방법과 Nvidia Docker, Nvidia Device Plugin을 활용하여 K8S 환경에서 GPU를 사용하는 방법에 관하여 다루어 보았다. 4-2에서는 RKE2를 사용하여 클러스터를 구축하고 Nvidia GPU Operator를 활용하여 K8S 환경에서 GPU를 다뤄볼 예정이다.
PS. 만약 RKE1 환경을 사용하던 중에 문제가 생겨 노드를 클러스터에서 제거하거나 노드를 초기화해야하는 경우라면 해당 강좌 3번글의 초기화 관련 정보를 읽어보도록 하자.
[K8S / Rancher 강좌] 3. Kubeadm을 통한 K8S 환경 구축 방법
목차 0. 우분투 환경 구축 1. Docker 설치 및 K8S를 위한 준비 2. Nvidia GPU가 달린 노드를 위한 기초 세팅 3. Kubeadm을 통한 K8S 환경 구축 방법 4. Rancher를 통한 K8S 환경 구축 방법 4-1. RKE1 (Docker) 환경에서 N
korjwl1.tistory.com
'프로그래밍|소프트웨어 > Rancher' 카테고리의 다른 글
| [K8S / Rancher 강좌] 4-2. RKE2 (Containerd) 환경에서 Nvidia GPU 사용 방법 (0) | 2023.09.01 |
|---|---|
| [K8S / Rancher 강좌] 4. Rancher를 통한 K8S 환경 구축 방법 (0) | 2023.08.20 |
| [K8S / Rancher 강좌] 3. Kubeadm을 통한 K8S 환경 구축 방법 (0) | 2023.08.19 |
| [K8S / Rancher 강좌] 2. Nvidia GPU가 달린 노드를 위한 기초 세팅 (0) | 2023.08.18 |
| [K8S / Rancher 강좌] 1. Docker 설치 및 K8S를 위한 준비 (0) | 2023.08.18 |



