
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- 가상컴퓨터
- Thunderbolt3
- 원격
- Code-Server
- 미니스튜디오
- 스마트 디스플레이
- SSD인클로저
- ACASIS
- k8s
- USB4.0
- 포토박스
- 울트라나브
- 탁상시계
- 미지아
- 트랙포인트
- Rocky LInux
- 빨콩
- 외장SSD
- centos
- talos linux
- k0s
- TRACKPOINT
- lubuntu
- Kubernetes
- IoT
- 시놀로지
- synology
- VMM
- lenovo
- 쿠버네티스
- Today
- Total
테크믈리에의 리뷰 공간
[K8S / Rancher 강좌] 4-2. RKE2 (Containerd) 환경에서 Nvidia GPU 사용 방법 본문
[K8S / Rancher 강좌] 4-2. RKE2 (Containerd) 환경에서 Nvidia GPU 사용 방법
테크믈리에 2023. 9. 1. 18:01
서론
이번 글에서는 RKE2를 기반으로 클러스터를 구축하고 해당 클러스터에서 GPU Operator를 사용하여 Nvidia GPU를 인식시키는 방법에 관하여 다루도록 하겠다. Nvidia Device Plugin, Node Feature Discovery 등에 관한 자세한 내용은 4-1번글에서 이미 다룬 바 있기 때문에 생략하고 설치 위주로만 글을 작성하도록 하겠다.
참고로 RKE1 클러스터에 GPU Operator를 사용하고자한다면, 이 글에서 Containerd 관련 내용을 전부 배제하고 진행한다면 거의 동일한 방법으로 환경을 구축할 수 있다.
RKE2 클러스터 구축

클러스터 구축의 경우, 4-1과 거의 비슷하게 진행되지만 차이가 있다면 Create 화면 상에서 RKE1이 아닌 RKE2/K3s를 선택해야한다는 것이다.

마찬가지로 Custom을 선택하면 위와 같은 화면으로 넘어올 것이다. 여기서 우리는 Containerd 기반 RKE2를 사용할 예정이기 때문에 버전은 자유롭게 고르되 RKE2에 해당하는 것만을 고르도록 하자.

별도로 필요한 내용이 없다고 한다면 기본 세팅 그대로 진행을 해도 되지만, 기본 세팅에 설정된 max pods의 갯수는 100개이기 때문에 부족하게 다가오는 경우가 많을 것이다. max pods를 늘리기 위해서는 Edit as YAML을 눌러 위와 같은 내용을 추가해주도록 하자.

성공적으로 클러스터 생성이 완료되었다면 위와 같은 화면이 나올 것인데, 대부분 단일 네트워크망 내에서 클러스터를 구축할 것이고 IP 기반으로 노드들을 관리하고 있다면 반드시 Reistration Command에서 Insecure 옵션을 체크해주도록 하자.
Nvidia Container Runtime 설치
이제 필요한 것은 Containerd에서 Nvidia GPU를 인식할 수 있게끔 해주는 런타임을 설치하는 것이다. GPU 활용이 필요한 각 노드에서 아래 명령어들을 입력하면 Nvidia Container Runtime의 설치가 완료된다.
curl -s -L https://nvidia.github.io/nvidia-container-runtime/gpgkey | \
sudo apt-key add -
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/nvidia-container-runtime/$distribution/nvidia-container-runtime.list | \
sudo tee /etc/apt/sources.list.d/nvidia-container-runtime.list
sudo apt-get updatesudo apt-get install -y nvidia-container-runtime
RKE2의 Containerd 설정
Nvidia Container Runtime을 설치한 다음에는 RKE2의 Containerd에서 runtime으로 nvidia runtime을 사용하도록 해줘야한다. Containerd는 기본적으로 config.toml이라는 파일을 통하여 설정값을 관리하는데, 해당 파일을 직접 수정하는 것이 아니라 config.toml.tmpl이라는 파일을 생성하여 설정값을 적어주면 Containerd를 재시작하면서 변경사항을 toml에 반영하는 식으로 동작한다.
우선은 toml 파일을 복사하여 tmpl파일을 만들고 파일을 열어 수정할 준비를 하도록 하자.
sudo cp /var/lib/rancher/rke2/agent/etc/containerd/config.toml /var/lib/rancher/rke2/agent/etc/containerd/config.toml.tmpl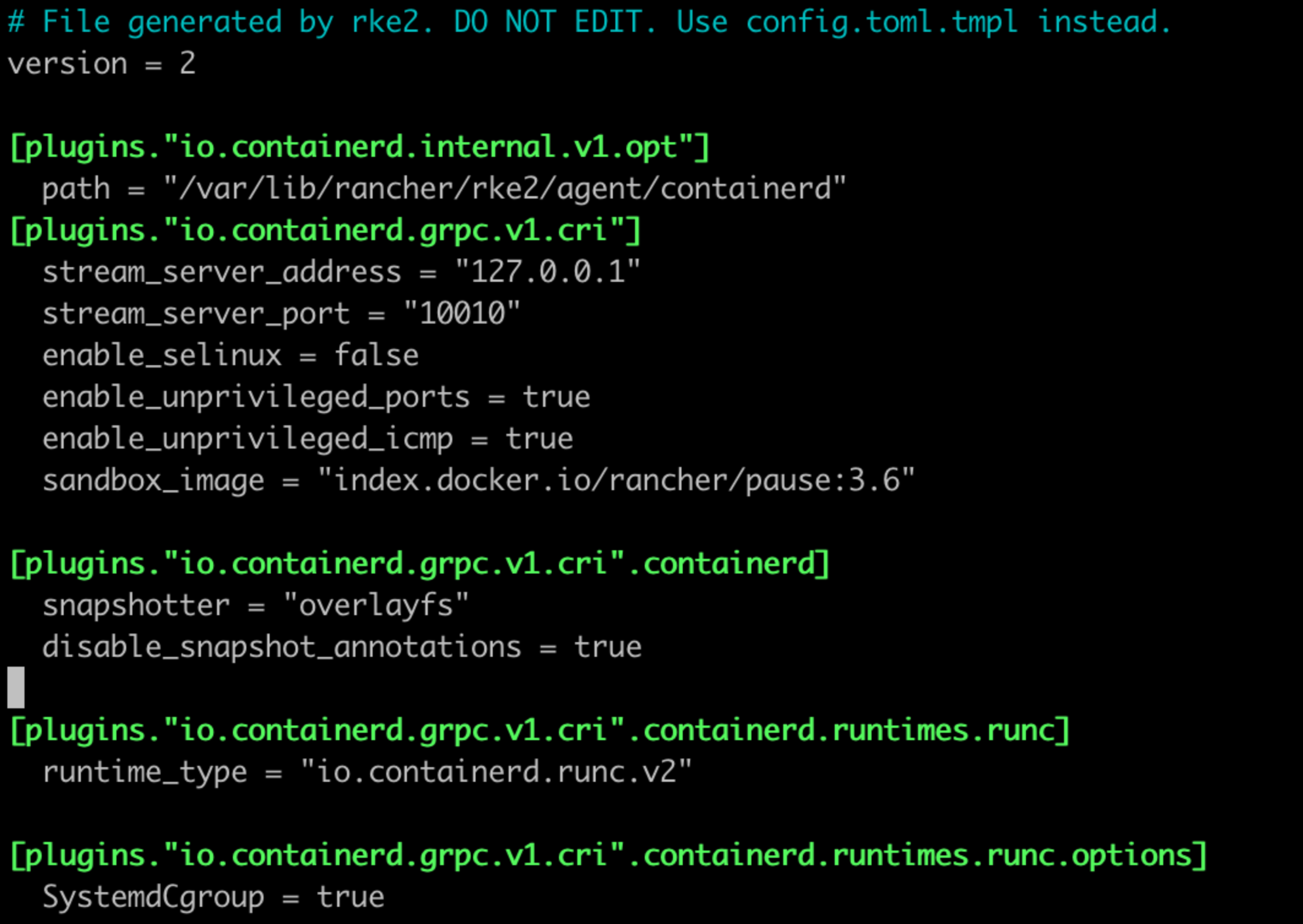
기본적으로 nvidia runtime 관련 내용이 반영되지 않은 tmpl 파일의 내용은 위와 같다. 여기서 "" 안에 들은 내용은 각자 다를 수 있다. 만약 위 사진과 "" 내부 내용이 다르다면, 위 사진과 같도록 수정하는 것이 아니라 해당 값을 참고하여 파일을 수정해야한다. 만약 위의 사진과 같이 nvidia runtime이 추가되지 않은 사람이라면 아래 사진을 참고해서 내용을 추가해야한다.
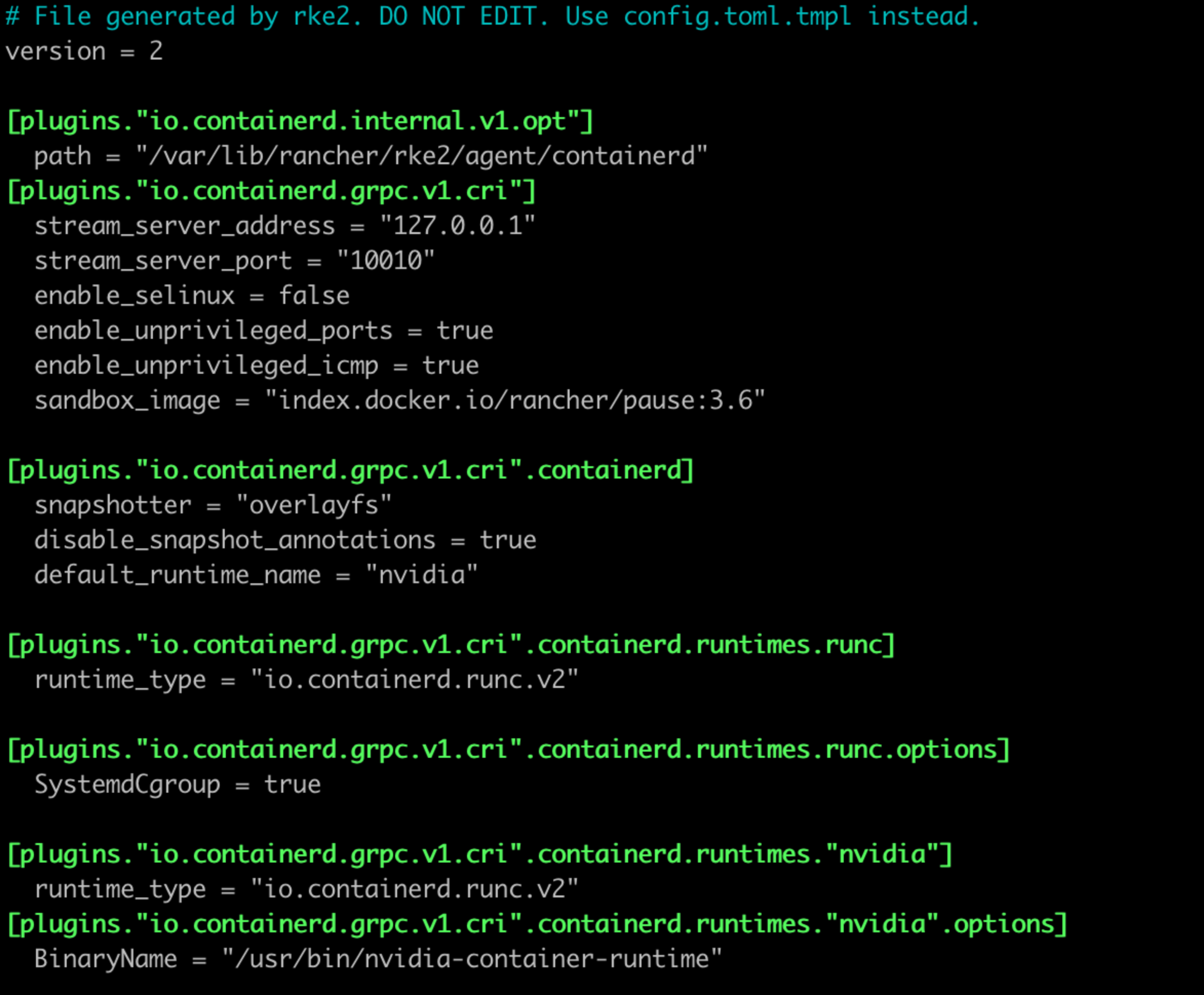
위 사진은 nvidia runtime 관련 내용이 추가된 파일의 내용물이다. tmpl의 원본 내용과 다른 점이라면 파일 중간에 default_runtime_name = "nvidia" 가 추가된 것과 파일 끝에 [plugins."~~".containerd.runtimes."nvidia"] 항목 및 [plugins."~~".containerd.runtimes."nvidia".options] 항목이 추가된 것이다.
sudo systemctl stop rke2-server.service
sudo systemctl restart rke2-server.service
sudo systemctl restart containerd파일 수정을 마쳤다면 위의 코드를 통해 rke2 서버 및 containerd를 재시작해줘야한다. 해당 서비스들을 재시작 하는 과정에서 오류가 발생한다면 다시 한번 tmpl 파일을 열어보도록 하자. 간혹가다가 마지막 두 항목이 자동으로 추가되어 본인이 삽입한 것과 중복으로 적혀있는 경우가 발생하는데, 그렇다면 본인이 적은 항목을 지우고 자동으로 삽입된 줄을 놔둔 다음 다시 서비스를 재시작해본다면 정상적으로 실행될 것이다.
Node Feature Discovery
NFD는 4-1과 마찬가지로 설치하면 된다. 자세한 내용은 4-1을 참조하고, 여기에는 설치를 위한 코드만 적어두도록 하겠다.

helm repo add nfd https://kubernetes-sigs.github.io/node-feature-discovery/charts
helm repo update
helm install nfd/node-feature-discovery --namespace node-feature-discovery --create-namespace --generate-name
GPU Operator 설치
이제 마지막으로 남은 것은 Nvidia에서 제공하는 GPU Operator를 올리는 것이다. 만약 RKE1에 설치하고 싶거나 공식 문서를 읽어보고 싶은 사람은 아래 링크를 참고하도록 하자.
Getting Started — gpu-operator 23.6.0 documentation
NVIDIA DGX systems running with DGX OS bundles drivers, DCGM, etc. in the system image and have nv-hostengine running already. To avoid any compatibility issues, it is recommended to have dcgm-exporter connect to the existing nv-hostengine daemon to gather
docs.nvidia.com
우선은 설치하기 전에 Helm Repo를 추가해주도록 하자.
helm repo add nvidia https://nvidia.github.io/gpu-operator && helm repo update그 다음에는 아래 명령어를 입력하여 Containerd 기반 환경에 GPU Operator를 올리도록 한다.
helm install gpu-operator -n gpu-operator --create-namespace \
nvidia/gpu-operator \
--set toolkit.env[0].name=CONTAINERD_CONFIG \
--set toolkit.env[0].value=/var/lib/rancher/rke2/agent/etc/containerd/config.toml.tmpl \
--set toolkit.env[1].name=CONTAINERD_SOCKET \
--set toolkit.env[1].value=/run/k3s/containerd/containerd.sock \
--set toolkit.env[2].name=CONTAINERD_RUNTIME_CLASS \
--set toolkit.env[2].value=nvidia \
--set toolkit.env[3].name=CONTAINERD_SET_AS_DEFAULT \
--set-string toolkit.env[3].value=true \
--set driver.enabled=false \
--set toolkit.enabled=false \
--set operator.defaultRuntime=containerd잠시 기지개좀 피고 와서 Rancher의 Cluster 관리 페이지에서 Nodes 항목으로 들어가 Label 항목을 보면 다음과 같은 내용이 추가되어 있다면 성공적으로 GPU Operator가 동작하고 있다는 의미이다.

마침글
이번 글에서는 RKE2를 기반으로 클러스터를 구축하고 Containerd 내용을 수정하고 GPU Operator를 올려 RKE2 환경에서 Nvidia GPU를 활용하는 방법에 관하여 다루어 보았다. 이론적으로 RKE2가 성능이 더 좋다고 하지만, 개인 경험 상 클러스터 Failure 케이스나 노드를 초기화하는 과정에서는 RKE1 대비 불안정한 면이 있었기 때문에 안정적인 환경이 필요하다면 RKE2 기반으로 모든 환경 구축을 완료하기 전에 이것저것 테스트 해보는 것을 추천한다.
'프로그래밍|소프트웨어 > Rancher' 카테고리의 다른 글
| [K8S / Rancher 강좌] 4-1. RKE1 (Docker) 환경에서 Nvidia GPU 사용 방법 (0) | 2023.08.20 |
|---|---|
| [K8S / Rancher 강좌] 4. Rancher를 통한 K8S 환경 구축 방법 (0) | 2023.08.20 |
| [K8S / Rancher 강좌] 3. Kubeadm을 통한 K8S 환경 구축 방법 (0) | 2023.08.19 |
| [K8S / Rancher 강좌] 2. Nvidia GPU가 달린 노드를 위한 기초 세팅 (0) | 2023.08.18 |
| [K8S / Rancher 강좌] 1. Docker 설치 및 K8S를 위한 준비 (0) | 2023.08.18 |



