
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 포토박스
- k8s
- TRACKPOINT
- synology
- 미지아
- 빨콩
- USB4.0
- Rocky LInux
- IoT
- lenovo
- k0s
- VMM
- 트랙포인트
- centos
- talos linux
- Kubernetes
- 쿠버네티스
- 울트라나브
- lubuntu
- 미니스튜디오
- 가상컴퓨터
- ACASIS
- SSD인클로저
- Code-Server
- Thunderbolt3
- 스마트 디스플레이
- 원격
- 시놀로지
- 탁상시계
- 외장SSD
- Today
- Total
테크믈리에의 리뷰 공간
K8S 환경에 CloudNativePG를 사용하여 PostgreSQL Cluster 구축하기 본문
- 서론 -

Kubernetes에 PostgreSQL 클러스터를 구축하는 방법은 몇가지가 있다.
우선 postgresql-ha 또는 postgresql cluster로 helm 차트 등을 검색하면 bitnami에서 제공하는 postgresql-ha가 나오는데, 해당 차트는 pgpool 미들웨어를 기반으로 High Availability를 제공할 수 있도록 구성된 차트이다.
해당 차트는 사용해보니 문제가 postgresql_conf 파일 수정이 번거로운데다가 잘 먹지 않는 값들도 있고 해서 안정적인 운용이 힘들었고, 부차적인 문제로 Reddit을 열심히 들여다보니 pgpool이라는 미들웨어를 통해 클러스터를 구축하기보다는 pgbouncer를 기반으로 k8s에 최적화된 CloudNativePG를 사용하는 것이 더 좋다고 하여 해당 방식으로 갈아타게 되었다.
- CloudNativePG -
CloudNativePG 공식 문서: https://cloudnative-pg.io/documentation/1.24/
CloudNativePG v1.24
CloudNativePG CloudNativePG is an open-source operator designed to manage PostgreSQL workloads on any supported Kubernetes cluster. It supports deployment in private, public, hybrid, and multi-cloud environments, thanks to its distributed topology feature.
cloudnative-pg.io
CloudNativePG 공식 GitHub: https://github.com/cloudnative-pg/cloudnative-pg
GitHub - cloudnative-pg/cloudnative-pg: CloudNativePG is a comprehensive platform designed to seamlessly manage PostgreSQL datab
CloudNativePG is a comprehensive platform designed to seamlessly manage PostgreSQL databases within Kubernetes environments, covering the entire operational lifecycle from initial deployment to ong...
github.com
CloudNativePG는 Kubernetes 클러스터 상에서 PostgreSQL을 보다 더 쉽게 관리할 수 있게 만들어진 Operator로 PostgreSQL DB들을 관리하고 Pooling Layer를 PgBouncer 기반으로 관리하며 부가 기능으로 Failover, Security, Replication 등을 제공한다.
앞서 소개한 Bitnami와 비교하자면, Bitnami의 차트는 단순히 PgPool 및 PostgreSQL을 컨테이너화한 다음 묶어서 제공할 뿐인 느낌이라 PostgreSQL 및 PgPool 관련 설정들도 단순히 value.yaml 등으로 적용하는게 쉽지 않아 전체 postgresql.conf 파일을 하나의 ConfigMap에 담아 적용하여 강제로 덮어써지도록 해야했지만 CloudNative는 간단한게 postgresql.cnpg.io/v1의 Cluster 똑는 Pooler kind 등 Operator에서 제공하는 형식의 yaml 파일을 작성하여 적용만 하면 된다는 점에서 매우 K8S 지향적이라는 생각이 들었다.
또한, 백업과 같은 것도 별도로 velero 같은 것을 사용하거나 PostgreSQL의 전통적인 백업 방법을 사용할 필요 없이 yaml 파일 하나만으로 스케쥴화해서 진행할 수 있다는 것도 큰 매력이다.
- 설치 -
이번 글에서는 간단하게 cluster 및 pooler를 원하는 대로 설정하여 동작 확인을 하는 것까지만 소개할 예정이다.
자세한 나머지 세팅은 공식 문서에 매우 잘 나와있으니 참조하도록 하자.
우선, CloudNativePG를 사용하기 위해서는 Operator부터 설치해야한다.
kubectl apply --server-side -f \
https://raw.githubusercontent.com/cloudnative-pg/cloudnative-pg/release-1.24/releases/cnpg-1.24.1.yaml

설치하고 나면 cnpg-system이라는 namespace가 생성되며, 그 아래에 cnpg-controller-manager가 떠있는 모습을 볼 수 있다.
이제 클러스터를 구축해보도록 하자.
아래의 코드는 본인이 사용한 cluster.yaml 파일로 본인의 환경에 맞게 수정하여 사용하도록 하자.
참고로 이전에 작성한 Elasticsearch 클러스터 구축 때와 마찬가지로 PostgreSQL 역시 저장소 I/O속도가 중요하며 자체적으로 Replica를 생성하기 때문에 Rook Ceph같은 분산 스토리지보다는 OpenEBS LocalPV 같은 저장소를 추천한다.
apiVersion: postgresql.cnpg.io/v1
kind: Cluster
metadata:
name: postgre-cluster
namespace: cnpg-cluster
spec:
imageName: ghcr.io/cloudnative-pg/postgresql:16.3-10
instances: 3
startDelay: 300
stopDelay: 300
# affinity:
# nodeAffinity:
# requiredDuringSchedulingIgnoredDuringExecution:
# nodeSelectorTerms:
# - matchExpressions:
# - key: postgre
# operator: Exists
storage:
size: 340Gi
storageClass: <본인이 사용할 storageClass>
walStorage:
size: 45Gi
storageClass: <본인이 사용할 storageClass>
postgresql:
parameters:
shared_buffers: 1GB
maintenance_work_mem: 256MB
wal_level: 'logical'
log_timezone: 'Asia/Seoul'
pg_hba:
- host all postgres all trust
resources:
requests:
cpu: 2
memory: 4Gi
limits:
cpu: 2
memory: 4Gi
# Rolling Update 관련 - https://cloudnative-pg.io/documentation/preview/rolling_update/
primaryUpdateStrategy: unsupervised
enableSuperuserAccess: true
# Grafana등 관련
monitoring:
enablePodMonitor: true
# 계정 관련
managed:
roles:
- name: myaccount
ensure: present
login: true
superuser: true
passwordSecret:
name: cnpg-user-myaccount
---
apiVersion: v1
kind: Secret
data:
username: <base64 인코딩된 본인이 사용할 계정>
password: <base64 인코딩된 본인이 사용할 비밀번호>
metadata:
name: cnpg-user-myaccount
namespace: cnpg-cluster
labels:
cnpg.io/reload: "true"
type: kubernetes.io/basic-auth
파일 작성이 끝났다면 아래 명령어로 해당 파일을 적용하도록 하자.
kubectl apply -f cluster.yaml
이제 생성된 클러스터에 외부에서 접근할 수 있도록 하기 위해서는 pooler 설정이 필수이다.
아래는 본인이 사용한 pooler.yaml 파일로 본인의 환경에 맞게 수정하여 사용하도록 하자.
apiVersion: postgresql.cnpg.io/v1
kind: Pooler
metadata:
name: cnpg-pgbouncer
namespace: cnpg-cluster
spec:
cluster:
name: postgre-cluster
instances: 3
type: rw
template:
spec:
containers: []
# affinity:
# nodeAffinity:
# requiredDuringSchedulingIgnoredDuringExecution:
# nodeSelectorTerms:
# - matchExpressions:
# - key: postgre
# operator: Exists
serviceTemplate:
metadata:
labels:
app: pooler
spec:
type: LoadBalancer
loadBalancerIP: ""
pgbouncer:
poolMode: session
parameters:
max_client_conn: "100"
default_pool_size: "10"
마찬가지로 kubectl apply -f를 통하여 파일을 적용하도록 하자.
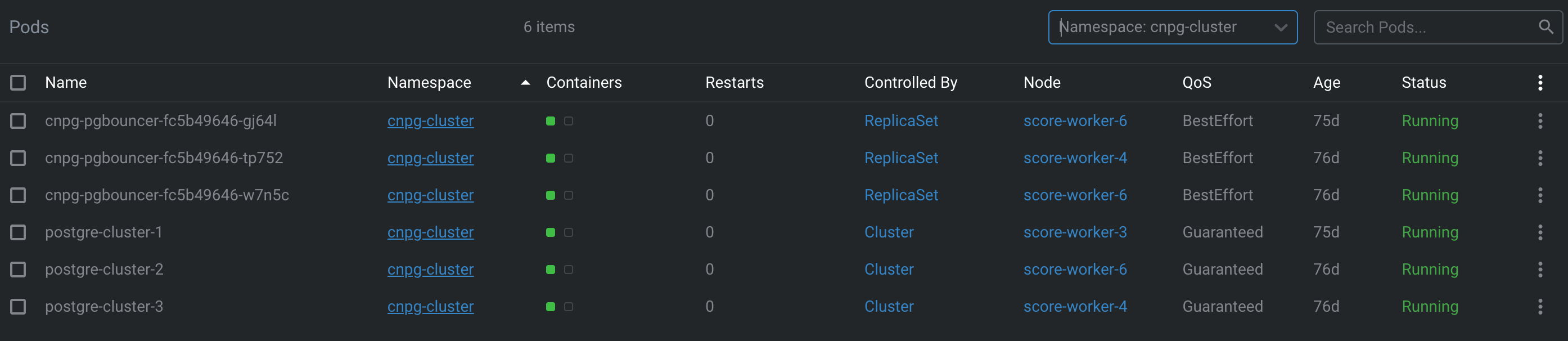
성공적으로 끝냈다면 위와 같이 postgre-cluster들과 cnpg-pgbouncer들이 cnpg-cluster namespace에 생성된 것을 확인할 수 있다.
'프로그래밍|소프트웨어' 카테고리의 다른 글
| OPNsense 설정기 2. SSL 인증서 관리 (0) | 2024.10.29 |
|---|---|
| OPNsense 설정기 1. HA-Proxy를 이용한 Reverse Proxy 구축 (1) | 2024.10.28 |
| Synology VMM 우분투 구축기 4. Code-Server 구축 (1) | 2021.09.23 |
| Synology VMM 우분투 구축기 3. VNC 서버 구축 (16) | 2021.09.23 |
| Synology VMM 우분투 구축기 2. Lubuntu 설치 (0) | 2021.09.23 |



